DeepSeek V3.1 Release: Higher Thinking Efficiency, the First Step Towards the Agent Era
The new DeepSeek-V3.1 has launched, almost six months after the DeepSeek-V3-0324 model. There was no prior announcement.

Since launching the DeepSeek-R1 model in January, DeepSeek has quietly made small updates to its models. First, the DeepSeek_V3_0324 model update arrived in March. Then, the DeepSeek-R1-0528 update came at the end of May. Both updates improved functionality and performance, but these were small changes. They weren’t big enough to need a new version number. The DeepSeek-V3.1 model is here. It shows a big boost in performance and competes strongly with OpenAI’s GPT-5 model.
The core change can be summarized in one sentence: One model, two experiences. You can now use hybrid inference. This lets users easily switch between thinking mode and non-thinking mode with the DeepThink button. Switch to thinking mode for detailed reasoning. Use non-thinking mode for simple answers. Official end-to-end products have all been upgraded at once. The website, app, mini-program, and API now use the new model called DeepSeek-V3.
Quick Summary
1. Hybrid inference mode, one model supporting free switching between thinking and non-thinking modes.
2. Significant efficiency improvement with faster speed and approximately 20-50 fewer output tokens.
3. Enhanced Agent capabilities with noticeably improved performance in programming and search agents.
4. Support for 128K long context, further strengthened compatibility, and continued open-source commitment.
What Does Hybrid Inference Bring?
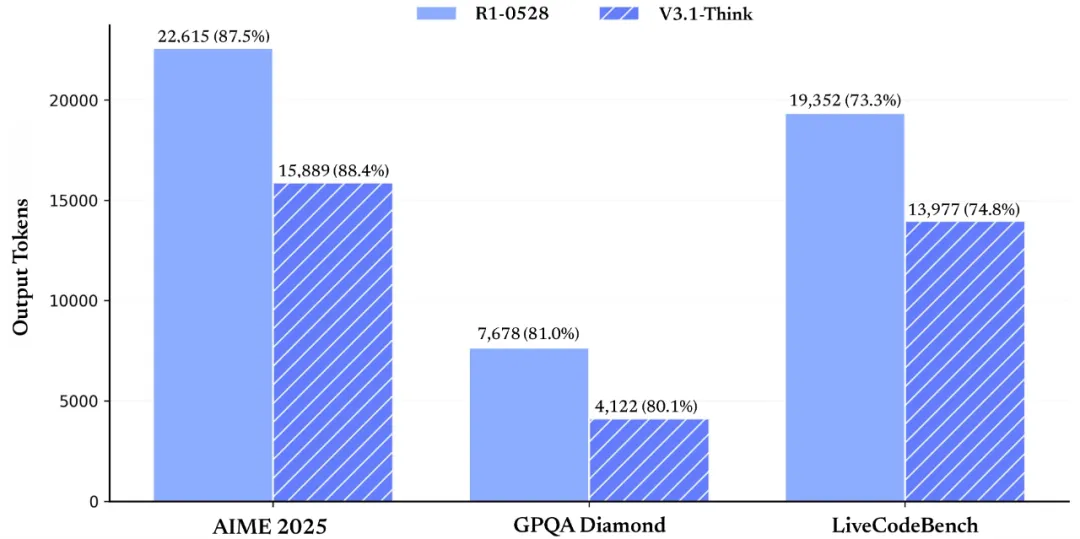
V3.1-Think delivers results like R1-0528 on various benchmarks, but it does so more quickly. On AIME 2025, R1-0528 scored 87.5 while V3.1 achieved 88.4. On GPQA, R1-0528 scored 81 compared to V3.1’s 80.1. On liveCodeBench, R1-0528 reached 73.3 while V3.1 hit 74.8. While maintaining comparable quality, V3.1-Think reduces output tokens by approximately 20-50. We’ve achieved the goal of making the model both perform better and consume fewer resources.
Independent analysis provides additional perspective. Artificial Analysis notes that V3.1 combines V3 and R1 into a hybrid inference model. It scores 60 in reasoning mode, up from R1’s 59. In non-reasoning mode, it scores 49, a big jump from V3 0324’s 44.
How Strong Are the Agent Capabilities?
DeepSeek says that V3.1 has made big strides in tool use and multi-step agent tasks. This post-training optimisation marks progress toward the Agent era.
The team used an internal code agent framework to test code repair skills on the SWE-bench test. The results showed that fewer rounds were needed compared to the open-source OpenHands framework. Code repair abilities also improved significantly over earlier DeepSeek models.
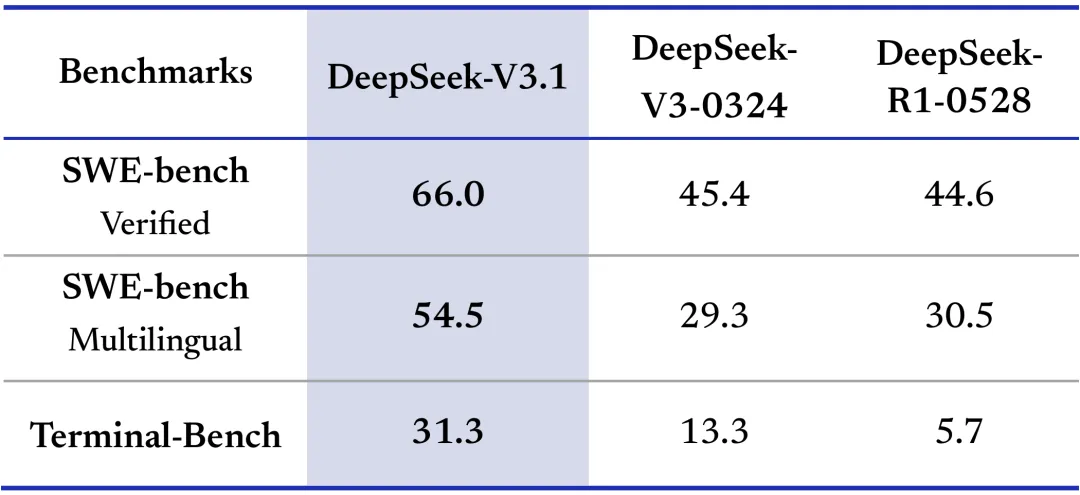
Testing on Terminal-Bench with the official Terminus 1 framework showed that terminal agents handled complex command-line tasks more reliably.
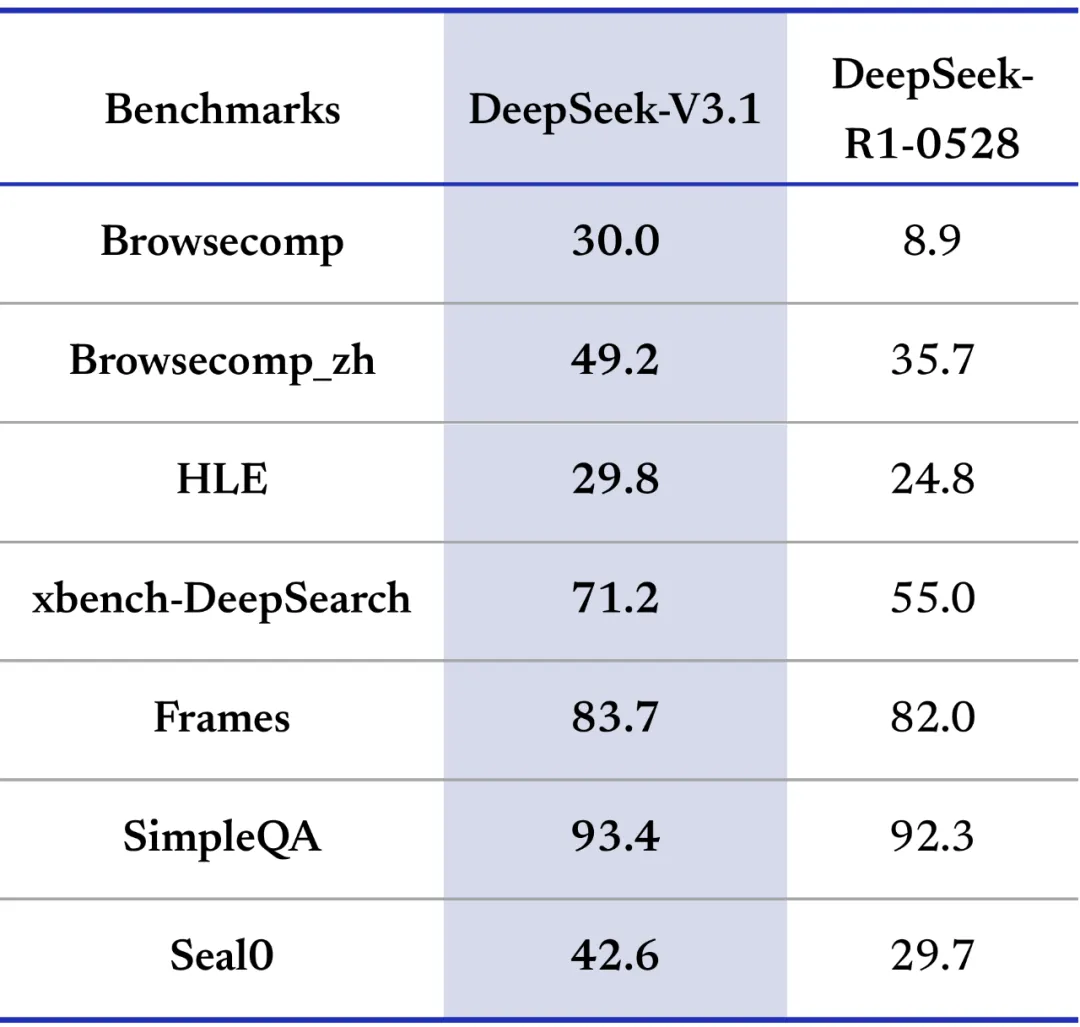
V3.1 offers a special search tool format for thinking mode. It supports complex multi-round search agents. In tests using commercial search APIs, web filters, and 128K context (with R1-0528 as a comparison), V3.1 showed clear benefits. It excelled in browsecomp tasks needing multi-step reasoning. There were also significant gains in the expert-level HLE challenge (text subset only). It handled complex problems well, especially those needing current or external information.
How Was the Technical Foundation Upgraded?
V3.1 is built on the brand-new V3.1-Base. The base model uses a two-stage method to extend context. It includes extensive training on the V3 checkpoint. The additional training volume amounts to 840 billion tokens.
The 32K extension stage achieved a 10x boost in training volume, hitting 630 billion tokens.
The 128K extension stage increased by 3.3x, reaching 209 billion tokens.
The team significantly expanded the dataset scale for both stages by collecting more long documents.
Training uses the UE8M0 FP8 scaling format and updates the tokenizer. Related settings are synced with the official GitHub and HuggingFace repositories. The team stated on the official WeChat public account that UE8MO FP8 is designed for the next generation of domestic chips. Developers planning to deploy should carefully read the documentation to avoid potential issues.
Product Form and API System
One clear change is that the web interface now just labels everything as “Deep Thinking.” It has removed the R1 designation from the Deep Thinking UI.” The online model has also expanded the context window from 64K to 128K. Additionally, DeepSeek has launched a new API service architecture:
- deepseek-chat: corresponds to non-thinking mode
- deepseek-reasoner: corresponds to thinking mode
Both support 128K context.
The Beta API supports strict mode Function Calling, ensuring output functions strictly adhere to the schema.
We added full support for the Anthropic API format. This makes it easy to integrate with Claude Code frameworks. Documentation available on the official website.
Both V3.1-Base and post-trained models follow the open-source tradition. You can download them on Hugging Face and ModelScope.
DeepSeek announced that the new pricing will start on September 6, 2025, at 00:00 Beijing time. Off-peak discounts will end at the same time. Until then, APIs will continue to be billed at current rates.

Community Experience and Discussion
Naming it V3.1 instead of the date-based V3-XXXX format has stirred speculation in the community. However, the official team hasn’t given a clear explanation. Following previous patterns, the model launch precedes detailed documentation and promotional materials.
After the new model launched, it quickly gained popularity on Hugging Face. It reached 4th place and later climbed to 2nd. Social media feedback has been mixed. Some see it as a foundation for V4 and R2, but others found it less impressive.
Numerous hands-on observations have emerged:
In programming tasks, frontend development skills have grown. Websites now have better layouts, richer content, and higher completion rates. It took about 2 minutes to recreate the Chrome Dino game, but there’s still room to enhance playability.
V3.1 offers richer information and detailed answers for niche historical questions. It has a warmer tone that shows context and complexity, avoiding simple, black-and-white conclusions.
In creative writing, it maintains the familiar style of using analogies and metaphors.
In mathematics, it gives correct answers for basic problems. However, it sometimes takes a winding path that needs reflection and correction.
In translation, it handles complex sentences better but occasionally misses common words.
Developers say that V3.1 creates more realistic bouncing effects. You can adjust parameters like gravity, friction, and rotation speed. Some have reported issues with the online API.
Benchmark testing of the non-reasoning model has also attracted attention. One tester scored 71.6 on aider. This is the SOTA for non-reasoning models. It’s about 1 percentage point higher than Claude Opus 4. Also, it provides much better cost-effectiveness. Community observations show that V3.1 has added 4 special tokens. It sometimes performs automatic searches, even when this feature is off. On SVGBench, the ranking is V3.1 > V3.1 Thinking Mode > R1-0528. These are community observations provided for reference only.
Practical Tips for Developers
Choose the right mode for the task:
- Thinking mode is best for multi-step reasoning, complex searches, and accessing external information.
- Non-thinking mode is more efficient for quick, stable responses.
Use the 128K context well. It helps with long documents, ongoing conversations, and combining tool outputs.
Here’s the simplified version:
Distinguish API endpoints:
- deepseek-chat: for casual conversations.
- deepseek-reasoner: for thoughtful reasoning. Both support a 128K context.
Select strict mode for Function Calling to ensure schema compliance.
Watch the compatibility layer. You can easily adapt existing frameworks using the Anthropic API. This makes for smoother experiences in Claude Code scenarios.
Read the documentation carefully before deployment. The FP8 scaling and tokenizer upgrades affect inference and service settings. This could lead to issues for developers who aren’t paying attention.
In a Word
V3.1 has changed hybrid inference into a switchable product. It combines speed, cost, and interpretability. The Agents show similar performance to R1-0528 but use fewer tokens. They also provide clearer pathways for programming, terminal operations, and search tasks. The technical foundation has stabilised 128K context using a two-stage extension. It’s also ready for future updates with UE8M0 FP8 and a new tokenizer. The API now has better entry points and improved compatibility. It also stays true to its open-source promise. Pricing will transition to the new schedule on September 6, returning to normal commercial operations.
This shows a systematic blend of V3 and R1, creating a hybrid engine that’s easy to control. V3.1 gives better options for creating content, doing research, and deploying in businesses. Thinking and speed are now two parts of the same interaction.


Stop purchasing blindly! Use Nano Banana Pro's AI to generate realistic furniture previews. Learn precise prompt engineering to visualize colors, Read more

It’s late December 2025. If your social feed looks anything like mine, the "Ice Angel" makeup look is back in full force, Read more

Tired of scrolling through terrible stock images with fake checkered backgrounds? Here is how to make your own custom graphics Read more

Seedream 4.5 offers stable characters, readable text, and consistent visuals—perfect for designers, artists, and quick, reliable AI-generated projects.


